
在走向通用东说念主工智能的说念路上,机器东说念主领域耐久濒临着“莫拉维克悖论”的截止:好多对东说念主类来说很清苦的事,AI 却很擅长;而好多对东说念主类来说胜券在握的事,AI 反而作念不到。
举例,让野心计在才略测试或棋类游戏中打败东说念主类或者相对容易,但要让机器东说念主像一岁孩子那样具备对物理天下的感知和通达本能,却难如登天。
连年来,妄言语模子展现了对东说念主类常识的压缩与生成才智,但在物理交互层面,如何让智能体清楚“动作”与“环境”之间复杂的因果关系,恒久是具身智能尚未攻克的难题。
近日,英伟达(NVIDIA)与其通工具身智能磋磨团队(GEAR)共 30 个作家归拢髻布了一项代号为 DreamDojo 的最新磋磨收场,试图从根蒂上影响机器东说念主学习物理天下的花式。

图 | 团队论文:DreamDojo:基于大领域东说念主类视频的通用机器东说念主天下模子(开头:GitHub)
这项使命并莫得依赖传统的、崇高的机器东说念主遥操作数据堆叠,而是匠心独具,构建了一个包含 44,000 小时、第一东说念主称视角东说念主类视频的高大数据库,并以此窥察出了一个能够通用化的机器东说念主天下模子。
这一模子不仅能够传神地生成物理交互视频,更要害的是,它让机器东说念主初度具备了可控的“想象力”。即在扩充动作之前,在潜意志中预演东说念主类天下物理后果的才智。

天下模子的观念仍是并不清新。从早期的游戏环境模拟到自动驾驶中的轨迹估量,估量将来景象一直是智能决策的中枢。然而,在怒放天下的机器东说念主操作任务中,天下模子的构建濒临着独有的挑战。与有着了了轨则的电子游戏或结构化说念路不同,家庭、工场或办公室等非结构化环境充满了不细目性。
举例一个看似毛糙的“握打水杯”动作,触及物体材质、摩擦力、液体回荡以及机械臂能源学等无数变量。此前的视频生成模子,如 OpenAI 的 Sora 或 Google 的 Genie,天然在画面生成质料上取得了破损,但它们大多穷乏精准的动作限定接口,难以直给与事于机器东说念主的决策回路。
{jz:field.toptypename/}而这次 DreamDojo 的中枢破损就在于此,它诠释了通过大领域的东说念主类视频预窥察,结合翻新的“潜在动作”(Latent Actions)表征,不错有用地弥合东说念主类与机器东说念主之间的“具身互异”(Embodiment Gap),从而让机器东说念主赢得对物理法例的通用清楚。
借力东说念主类视频破损数据缺口
耐久以来,制约机器东说念主基础模子发展的最大瓶颈在于数据。尽管互联网上充斥着万亿级别的文本和图像数据,但高质料的“机器东说念主操作数据”。即包含精准动作教导(Action Labels)和环境反馈的序列数据却相等稀缺。当今主流的机器东说念主数据集,如 Open X-Embodiment,天然汇集了多个实验室的数据,但在场景各类性和物理交互的丰富度上,仍远不及以遮盖实在天下的复杂性。
英伟达团队意志到,单纯依靠扩大机器东说念主实体数据的集聚领域是不现实的。集聚老本兴盛、硬件损耗大、场景叮嘱繁琐,这些身分截止了数据的增长速率。比较之下,东说念主类在浩荡糊口中无时无刻都在与物理天下交互,而这些交互过程要是被记载下来,自己即是蕴含着丰富物理常识的宝库。
为了挖掘这一宝库,磋磨团队构建了名为 DreamDojo-HV(Human Videos)的数据集。这是一个领域惊东说念主的数据逼近,包含了约 44,711 小时的第一东说念主称视角视频。
这些视频并非来自于受控的实验室环境,而是凡俗集聚自实在天下,涵盖了家庭烹调、工业维修、手工制作、浩荡清洁等最初 6,000 种独有的技巧和 1,000 多种不同的场景。为了保证数据的各类性,团队还零散整合了 EgoDex 等现存的高质料数据集,使得 DreamDojo-HV 在领域上比此前机器东说念主学习中使用的最大视频数据集还要大出几个数目级。
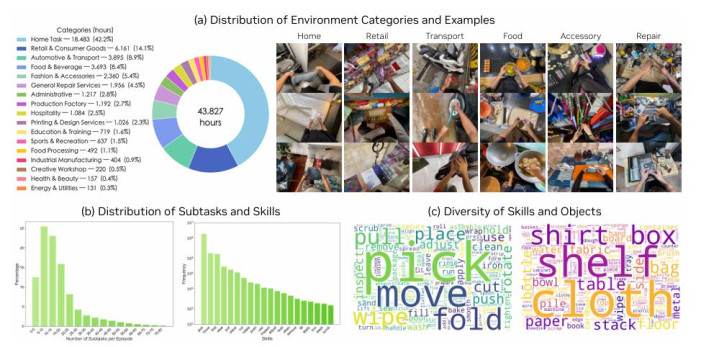
图 | DreamDojo-HV(Human Videos)的场景散播(开头:论文)
然而,径直使用东说念主类视频窥察机器东说念主模子也濒临着一定清苦。最直不雅的问题是:东说念主类的手臂结构与机器东说念主的机械臂完全不同,且东说念主类视频中并不包含机器东说念主的关节角度、力矩等限定信号。这种缺失导致模子难以径直学习“动作”与“收场”之间的映射关系。
逐帧推理下一个动作
为了处治无标签东说念主类视频的运用问题,DreamDojo 引入了一项要害时候:连气儿潜在动作(Continuous Latent Actions)。
在传统的机器东说念主学习中,模子时常径直估量破碎的关节动作或终局扩充器位姿。但在处理海量无标注的东说念主类视频时,这种要道行欠亨了。因此,磋磨东说念主员想象了一个基于时空 Transformer 的变分自编码器(VAE)动作“潜在动作模子”。
这个模子的作用雷同于一个能够清楚动作本色的“翻译官”。它不脸色具体的关节如何旋转,而是通过不雅察视频中连气儿帧的变化,索求出一个低维的、连气儿的潜在向量。这个向量代表了导致环境发生变化的“意图”或“力学特征”。

图 | 潜在动作模子(开头:论文)
通过这种想象,潜在动作成为了勾通东说念主类视频与机器东说念主限定的通用桥梁。在预窥察阶段,模子通过自我监督的花式,学习如何从像素变化中想到出潜在动作,并运用这些潜在动作估量下一帧画面。
这使得 DreamDojo 能够在莫得显式动作标签的情况下,从 44,000 小时的视频中继承物理天下的因果逻辑。举例,它通过不雅察无数次“手推开门”的视频,学会了“施加推力”这一潜在动作会导致“门掀开”这一视觉收场的物理法例,快乐飞艇而这种法例关于机器东说念主来说相同适用。
在具体的模子架构上,DreamDojo 设立在英伟达此前发布的 Cosmos-Predict2.5 基础之上。这是一个苍劲的潜在视频扩散模子(Latent Video Diffusion Model),底本用于通用的视频生成。为了顺应机器东说念主的及时限定需求,磋磨团队对其进行了深度的改革。
为了提高动作的可控性,团队毁灭了皆备关节位置的输入花式,转而采用“相对动作”(Relative Actions)动作条款。实验标明,相对动作能够更好地聚焦于物体与手部的交互变化,减少了布景环境对模子注意力的分散。
同期,针对视频生成中常见的“因果污染”问题,即模子难以分手动作是原因如故收场。磋磨团队提议了一种“分块注入”(Chunked Injection)战略。
他们将将来的动作序列打包成块,一次性输入到模子的每一帧生成过程中。这种强先验信息强制模子脸色永劫程的动作影响,从而权臣擢升了生成视频的逻辑连贯性。
此外,为了确保生成的物理过程相宜现实天下的连气儿性,磋磨团队还引入了有利的时刻一致性蚀本函数(Temporal Consistency Loss)。这一函数约束了物体在时刻轴上的通达轨迹,贯注了视频生成中常见的物体精通、假造灭绝或局面突变等伪影表象,确保了物理模拟的高保真度。
从慢速扩散到超快及时“想象”
领有一个懂物理的模子仅仅第一步,关于机器东说念主应用来说,推理速率至关热切。传统的视频扩散模子生成一帧高质料画面常常需要数十次迭代,耗时数秒,这关于需要毫秒级反映的机器东说念主限定回路来说是不成接受的。
为了处治这一难题,DreamDojo 采用了一种名为“自将就”(Self Forcing)的蒸馏时候,收效将底本坚苦的双向注意力扩散模子转变为高效的自追想模子。
这一过程通过“锻练-学生”窥察模式已毕:发轫运用高精度的锻练模子生成多数的轨迹数据,然后窥察学生模子去师法这些轨迹。但在蒸馏过程中,学生模子不仅要学习单帧的生成,还要学习如安在仅有极短历史陡立文的情况下,估量将来的耐久演变。
这一蒸馏过程将模子的推理步数从底本的 35 步大幅压缩至 4 步。最终,DreamDojo 在单张 NVIDIA H100 GPU 上已毕了 10.81 FPS(帧/秒)的及时推理速率。这意味着机器东说念主不错在不到 0.1 秒的时刻内,在“脑海”中生成将来的视觉反馈。
这不仅知足了及时限定的要求,更让永劫程的交互模拟成为可能。实验清爽,经过蒸馏后的模子能够连气儿生成长达 1 分钟(约 600 帧)的褂讪视频,且在永劫刻跨度下依然保持对物体零散物理属性的挂牵,莫得出现常见的画面崩坏。
买通“虚实”鸿沟的试验应用
DreamDojo 的价值远不啻于生成传神的视频,其实质是为机器东说念主提供了一个低老本、高保真实“试错空间”。基于这一生界模子,英伟达团队展示了三项中枢应用,充分诠释了其在机器东说念主研发与部署历程中的后劲。
发轫是战略评估(Policy Evaluation)。在机器东说念主斥地中,考据一个新的限定战略时常需要实机测试,这不仅服从低下,还伴跟着硬件损坏的风险。DreamDojo 提供了一个替代决策:将战略部署辞天下模子中,让机器东说念主在虚拟的视频流中扩充当务。
磋磨东说念主员在 AgiBot 机器东说念主的生果包装任务中进行了考据,收场令东说念主激昂:DreamDojo 模拟出的任务收服从与实在天下的收服从呈现出极高的线性联系性(Pearson 相关扫数高达 0.995)。这意味着斥地者不错定心性在模拟环境中筛选最优战略,而无需在现实天下中进行成百上千次的物理实验。
其次是基于模子的规画(Model-based Planning)。运用 DreamDojo 的估量才智,机器东说念主不错在扩充动作之前,在“想维”中并行推演多种动作决策的收场。
举例,在握取一个被阻扰的苹果时,机器东说念主不错预演径直握取和先移开阻扰物两种决策,DreamDojo 会即时生成相应的将来视频。通过评估视频中的任务完成度,机器东说念主不错选拔最优旅途。实验标明,在引入这种在线规画机制后,机器东说念主在复杂长程任务中的收服从比较径直扩充战略擢升了近两倍。
终末是及时遥操作(Live Teleoperation)。借助蒸馏后的高推理速率,操作员不错通过 VR 手柄及时初始虚拟环境中的机器东说念主。DreamDojo 能够即时反映操作员的动作,并生成相应的视觉反馈。这种“所见即所得”的零延伸体验,不仅为而已限定提供了新的界面,也为东说念主类向机器东说念主演示复杂技巧提供了更直不雅的数据集聚花式。

图 | 及时遥操作:不错使用 PICO VR 限定器及时遥操作虚拟 G1 机器东说念主(开头:论文)
天然,DreamDojo 并非简约绝伦。英伟达团队在诠释中坦诚地指出了刻下模子的局限性。尽管在大部分浩荡场景中推崇优异,但在面对一些顶点动态(如快速挥手、物体高速碰撞)或触及复杂流体能源学(如倒水时的水流湍流)的场景时,生成的视频仍会出现物理失真或无极。
此外,天然模子在未见过的物体上展现了细致的泛化性,但关于完全生分的物理机制(举例具有特别弹性的软体材料),其估量才智依然有限。
此外,当今的 DreamDojo 主要侧重于视觉层面的物理模拟,尚未整合触觉、听觉等多模态信息。关于像“盲插钥匙”或“判断物体分量”这么相等依赖触觉反馈的邃密操作任务,单纯依靠视觉估量的天下模子仍显过劲不从心。将来的磋磨方针可能需要探索如何将触觉信号引入潜在动作空间,构建愈加万能的多模态天下模子。
参考勾通:
运营/排版:何晨龙
 备案号:
备案号: